
noindexとrobots.txtを使ったインデックス制御術
Webサイトを運営するうえで、「このページは検索結果に表示したくない」「逆に、この商品ページは確実に表示してほしい」という状況は日常的に発生します。とくにECサイトでは商品数やページ数が膨大になる傾向があり、誤った設定が大規模なインデックス漏れやサーバー負荷の増大を招くリスクが高いです。
本コラムでは、検索エンジン(特にGoogleとBing)における**「noindexメタタグ」と「robots.txt」**の正しい使い分け方について、ECサイト運営者にも役立つ視点を交えつつ詳しく解説します。検索結果に意図しないページが出てしまうことを防ぎ、必要なページだけを効果的にインデックスさせるための方法を体系的に整理しました。
Contents
はじめに:インデックス制御の重要性
検索エンジンはクローラによってウェブを巡回(クロール)し、そのページ情報をデータベースに登録(インデックス)します。これにより検索結果が生成されるわけですが、運営者としては**「見られると不都合なページ」「公開していても検索結果には不要なページ」「SEO的に価値が薄いページ」**などを意図的に外したい場合があります。
- ECサイトの具体的な例
- 購入フロー(ショッピングカート~注文完了ページ)
- ログインやマイページなどの会員向け画面
- 内部検索結果やソート結果のような大量生成ページ
- テスト公開しているイベントページの下書き・仮ページ
こういったページが検索結果に表示されると、ユーザーの混乱を招くばかりでなく、サイト全体の評価にも悪影響が生じる可能性があります。「noindexメタタグ」と「robots.txt」は、こうしたインデックスから除外したいページやクローリングされる必要のないリソースを管理する上で不可欠です。ただし両者の役割は微妙に異なるうえ、組み合わせ方を間違えると想定外の結果を招くリスクもあります。まずはそれぞれの基本を把握し、適切な運用を目指しましょう。
noindexメタタグとは何か
noindexの基本的な役割
noindexメタタグは、HTMLの<head>内に記述して検索エンジンに「このページを検索結果に載せないでください」と伝えるための指示です。たとえば以下のように記述します。
<head>
<meta name="robots" content="noindex, follow">
</head>
このタグをクローラが読み取ると、該当ページはインデックスに登録されず、検索結果に表示されなくなります。なお「follow」を付けることで、ページ内にあるリンクはそのまま辿ってもらえます。ここで押さえるべき大切なポイントは、noindexの指示がクローラに伝わるにはページがきちんとクロールされる必要があるということ。もし何らかの理由でクローラがページにアクセスできなければ、noindexが設定されていること自体がわからないため、除外処理が行われない可能性が生じます。
GoogleとBingでの違い
GoogleとBingにおいては、noindexメタタグの取り扱いはほぼ同じです。いずれの検索エンジンでも、クローラがページを取得し、メタタグを確認した段階で「インデックスから外す」動作が行われます。かつては「robots.txtファイル内にnoindexと書くことでインデックスを制御する」といった手法も一部で使われていましたが、現在Googleはrobots.txtでのnoindex指定をサポートしていないと正式にアナウンスしており、Bingも同様です。
したがってページ単位で「検索結果に載せたくない」場合は、HTMLメタタグでnoindexを設定するのが唯一確実かつ正しい方法といえます。
noindexを使うシーン
- 機密情報・会員専用ページ
ログインしないと閲覧できないページはそもそも検索エンジンに見られる可能性が低いですが、ログイン画面や退会画面、パスワード再設定画面などが「検索結果に不要」である点は明らかです。ECサイトでもマイページや配送先情報の登録画面などが代表例として挙げられます。意図せず検索経由でユーザーがアクセスすると混乱を招くため、noindexを付けて除外しておくのが基本です。 - カートページ、注文完了ページ
ショッピングカートや注文完了ページは、SEO的にまったく価値がないばかりか、外部からのアクセスでエラーが起きたり、重複した注文が発生したりと問題につながります。またユーザーのプライバシー保護の観点からも、サンクスページ(注文後の確認ページ)が検索結果に出るのは好ましくありません。したがって「カート」「チェックアウト」「サンクスページ」には積極的にnoindexを指定することを推奨します。 - テスト公開・一時的ページ
新しいキャンペーンページをテスト実装している段階や、準備中のLP(ランディングページ)がある場合、ひとまず外部から閲覧はできるが検索結果には出したくない、という状況がしばしばあります。この場合もnoindexメタタグを利用してインデックス回避をしつつ、完成したらタグを外して検索エンジンに認識させる運用が一般的です。 - 重複コンテンツの対策
重複ページや類似性の高いページが複数生成されるサイト(例:ECサイトのソート結果やパラメータ違いでURLが増えるケース)では、主要なページ以外をnoindexにすることで検索エンジン上の重複コンテンツ扱いを回避できます。もっとも、重複コンテンツ問題には「canonicalタグ」の活用も併せて検討するのが通例です。どれを正式な正規ページとして認識させるかはケースバイケースで調整してください。
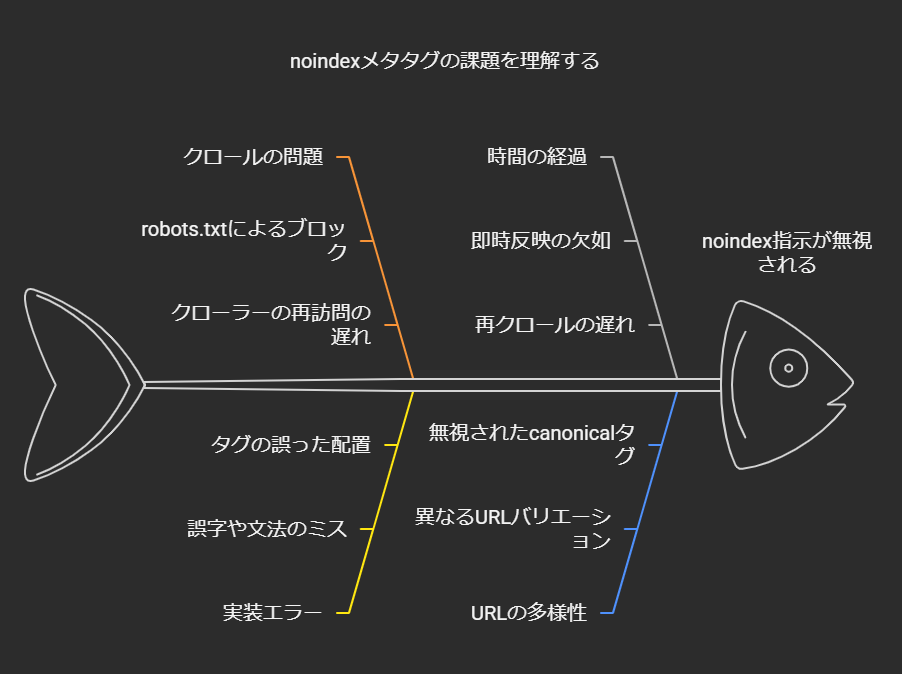
よくあるトラブル:noindexなのにインデックスされている?
「noindexを設定したのに検索結果に残ってしまう」というケースは以下のような理由で発生しがちです。
- robots.txtでブロックしている
robots.txtで該当URLをDisallowしていると、クローラはページにアクセスできません。つまりnoindexメタタグを見られないので、指示が伝わらず結局インデックスに残る可能性があります。 - 実装して時間が経っていない
クローラが再訪問するまでインデックスから外れません。場合によっては数日から数週間かかることもあります。早期反映を望むならSearch Console/Bing WebmasterツールなどでURL検査を行い、再クロールを促すとよいでしょう。 - ミススペル・設置場所の誤り
<meta name="robots" content="noindes">のように誤字がある、または<body>内にタグを置いてしまったなど、単純なケアレスミスが原因となることも。必ず正しい書式・位置に記述する必要があります。 - URLのバリエーション違い
WWWの有無・HTTP/HTTPS差分・パラメータが異なるだけで別URLと判断され、そちらにはnoindexが設定されていないというケースもあります。サイトの正規化ルール(canonicalタグや301リダイレクトなど)をしっかり設計することが大切です。
robots.txtとは何か
robots.txtが担う「クロール制御」
robots.txtはウェブサイトのルートディレクトリ(例:https://example.com/robots.txt)に配置され、クローラに対して「ここはクロール(アクセス)してもよい/してはならない」を通知するファイルです。これは「Robots Exclusion Protocol」と呼ばれる古くからの慣習的ルールに基づいており、GoogleやBingなど主要クローラはほぼ遵守しています。
記述の基本は以下のようにシンプルです。
User-agent: *
Disallow: /secret/
Allow: /secret/only-this-file.html
User-agent:はクローラ名を指定(*はすべてのクローラを対象)。Disallow:はクロールを禁止したいディレクトリやファイルへのパス。Allow:は部分的にクロールを許可したい例外パス(Googleなど主要検索エンジンでサポート)。
例えばWordPressでは管理画面へのアクセスを防ぐために以下のような設定がよくあります。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
これにより、/wp-admin/ 以下はクロール禁止としつつ、AJAX通信のためのadmin-ajax.phpは許可するという制御が可能です。
インデックスは制御できない?
robots.txtは「クロールしてほしい・してほしくない」を指示するだけであって、「検索結果に載せる・載せない」を直接指定する仕組みではありません。極端な例を挙げれば、
User-agent: *
Disallow: /test/
この記述をしていても、もし外部サイトからhttps://example.com/test/にリンクがあれば検索エンジンはURLを認識し、内容をクロールできないまでも「存在するページ」として検索結果に載せてしまうことがあります。その場合、「このページの説明は利用できません(robots.txtによりブロックされています)」と表示され、いわゆるスニペットが出ずにURLだけが検索結果に残る状態になるわけです。
つまり、「インデックスから確実に排除したい」ならページにnoindexを設定しなければならないという原則が成り立ちます。robots.txtでブロックしているだけではURLが検索結果に現れる可能性を排除しきれません。たとえ中身のテキストは表示されなくても、URLが世間に出回っている以上、検索エンジンのインデックスから完全に消すのは難しいのです。
ECサイト運営におけるrobots.txtの活用
ECサイトでは商品ページのボリュームが大きく、またカテゴリ・タグ・検索結果・フィルタリングなど多彩なページが乱立する傾向にあります。このとき、クロールさせてもメリットが無いページはあらかじめrobots.txtでまとめて遮断する方法がよく検討されます。
- 検索結果URLをブロック
たとえば/search?を含むパスはすべてDisallowすることで、内部検索の結果ページが不要にクローラに費やされるのを防げます。ECサイトの場合、検索キーワードや並べ替え条件を変えるたびに無数のページが生成されがちなので、クロール負荷が膨大になるリスクを軽減できます。
ただし、この手法だけでは「検索結果にURLが残るかもしれない」点には留意が必要です。結局、URLを見られるだけで困るという場合(プライバシー情報など)は別途noindexの対応や本質的なアクセス制限が求められます。 - 画像やリソースのブロック
商品画像はGoogle画像検索に載せるメリットがあるケースも多いですが、中には製品カタログ用の素材画像や、まだ公開前の素材が含まれる場合もあるでしょう。そういった「検索エンジンに見られると困る画像ディレクトリ」を一括でDisallowするなどの使い方が考えられます。PDFカタログ類でも同様です。 - クロール予算の節約
大規模ECの場合、「クローラがサイト内の本当に重要なページを見つけ出す前に、不要なURLばかりクロールしてクロールバジェットを使い切ってしまう」という事態が起こりやすくなります。robots.txtで不必要なパスを制限し、クローラが効率良く商品ページに到達できる環境を整えることは、ECサイトのSEO戦略上とても重要です。
設定ミスの危険性
robots.txtはシンプルなファイルですが、設定を一つ誤ると大きな被害を招く可能性があります。
- Disallow: /
サイト全体をブロックする最悪の記述です。開発環境でテストする際にこう書いていたのを、本番公開時に外し忘れてしまい、検索結果から全ページが消える事故が実例としても報告されています。 - 不要ページまでAllowしている
先述のように、具体的なAllowはより抽象的なDisallowよりも優先されるというルールが存在します。たとえばDisallow: /private/としたつもりが、誤ったAllowの記述で実質的に/private/の一部が許可されてしまうケースもあります。サイト運営の担当者が増えると、robots.txtの追記やメンテナンスで意図せぬ競合が起きがちなので注意しましょう。 - クローラのUser-agent指定の間違い
GooglebotとGooglebot-ImageやBingbotなど、名前が類似していて紛らわしいものがあります。適切にUser-agentを指定しないと、期待したクローラが従ってくれない事態が起こり得ます。通常はUser-agent: *として全クローラ共通ルールを定義し、もし特別な対応が必要なクローラがあれば別途セクションを追加する形にすると、ミスが少なくなるでしょう。
noindexとrobots.txtの使い分け
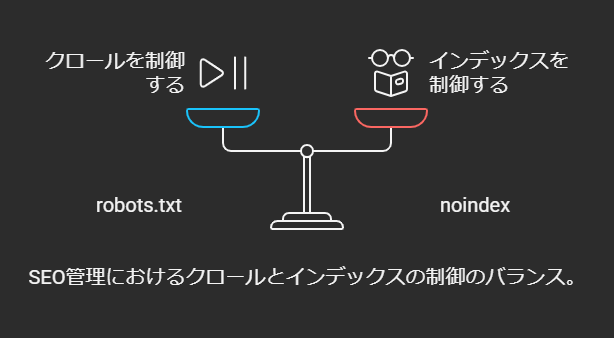
「検索結果に載せたくない」ならクロールさせる必要がある
一見すると矛盾しているように思えますが、「検索結果に表示したくないページほど、むしろクロールは許可すべき」というのがnoindexの基本ロジックです。ページ内容をクロールされることで検索エンジンはメタタグを確認し、「このページはインデックスしないようにしよう」と認識します。
もしrobots.txtで「Disallow」してしまうと、クローラはHTMLを一切取得できず、noindexタグの存在を知ることができません。結果として、URLだけが他サイトからリンクされている場合には検索結果に浮上し続ける可能性が残ります。
たとえばECサイトのカートページなどは、運営者としては見られたくない一方でnoindexだけは確実に読み込んでほしいページの代表例といえるでしょう。
「中身を見せたくない」ならrobots.txtでブロック
逆に、クローラに内容を見せるメリットが全くなく、読み込まれると負荷が大きい・セキュリティリスクがあるといった場合はrobots.txtでブロックするのが妥当です。たとえば管理画面やサーバー内部で使うツール類を配置しているディレクトリなどは、検索エンジンに限らず外部クローラからのアクセスを避けたいでしょう。
ただし機密性の高い情報に関しては、robots.txtだけでは不十分です。あくまで「ロボットの自主ルール」でしかないため、悪意のあるクローラには通用しません。本当に守りたいページやファイルにはパスワード保護やIP制限をかけるなど、別途対策を施しましょう。
併用時の注意
ECサイトではページによって「noindexで制御したいもの」「robots.txtで制御したいもの」が混在するのが一般的です。たとえば「ユーザーのマイページ」はnoindexを付けてクロールは許可しつつインデックスを防ぐ。一方で「内部検索結果のURL」は完全にクロールさせたくないのでrobots.txtで一括遮断する、という使い分けです。
ここで**やってはいけないのが「同じURLにnoindexとrobots.txtを同時適用」**することです。意図としては「より完全に隠す」つもりかもしれませんが、実際には先述の通りクローラがnoindexタグを読めなくなり、インデックス除外が無効化される場合があります。運用フローを決める際には、「noindexを仕込むページはrobots.txtでブロックしない」といったルールを社内で明確にしておくとよいでしょう。
ECサイトにおける具体的なインデックス制御例
カートページ
事例: 大手ECサイトA社
- カートページのURLは
/cart/で始まる。 - カート内容がユーザー固有のセッションにより生成される仕組み。
- カートページ自体にはSEO上の価値がなく、むしろ商品があるべき検索順位を押し下げる可能性がある。
対応:
- カートページに
<meta name="robots" content="noindex, follow">を設定。クローラはページ内容にアクセスできるものの、インデックスには登録されない。リンクを辿る必要が特になければ、follow部分は省略してnoindexのみでもOK。 - robots.txtでは
/cart/をブロックしない。ブロックするとnoindexが機能しなくなるから。 - 結果、クローラは自由にカートページをクロールできるが「noindex」という指示を読み取りインデックスしない。検索結果に余計なカートURLが出ることを防ぎつつ、クローラがサイト構造を理解する機会も損なわない。
会員ページ(マイページ等)
事例: 会員制ECサイトB社
- マイページやプロフィール編集ページが多数。
- ログインなしでもURLパスを推測してアクセスすれば画面が表示されてしまう構造(ただし実際の個人情報はログインしないと見えない)。
- 検索結果には不要どころかプライバシー上の懸念も。
対応:
- まずはシステム面で未ログイン時のアクセス制御を行うことが大前提。マイページ自体を完全にブラウザ表示不可にするか、無意味なエラー画面を返すなど検討する。ただし「ログイン画面に飛ばすだけ」という挙動だと、ログインページが検索に出てしまうリスクは残る。
- ログインページやマイページのURLには、できる限り
noindexを付与。 - ただし内部のシステムによってはHTMLの編集が難しい場合もある。この場合、HTTPヘッダーで
X-Robots-Tag: noindexを返す運用を検討するとよい。サーバーサイドでレスポンスヘッダを設定しておけば、HTMLを直接修正しなくてもnoindex指定が可能になる。 - もしマイページにログインしないと入れない仕組みなら「そもそも検索エンジンが内容を見られない」ので、インデックスされるリスクは低い。ただしURLがある程度容易に推測でき、外部からアクセスされた場合ログインページにリダイレクトする仕組みになっていると、ログインページが検索結果に出てくることはしばしば起こる。これもnoindexで抑止しておくと安心。
サイト内検索結果
事例: 大規模ECサイトC社
- サイト内検索機能があり、商品名・カテゴリー・価格帯など条件を変えたURLが大量に発生。
- 商品点数が数万~数十万点規模であり、検索結果URLが指数的に増える可能性がある。
対応:
- サイト内検索結果が「特に価値のある独自コンテンツを持たない」のなら、ほぼすべてrobots.txtでブロックしてしまうのが有効。たとえば
/search?で始まるパラメータ付きURLをDisallow: /search?とすれば、クローラは該当URLにアクセスしなくなる。 - これによりクローラーが無限に近い検索結果ページをたどる無駄がなくなるため、クロールバジェットの浪費を防げる。
- もし検索結果ページに一部オリジナルの説明文やランキング情報などがあり、検索ユーザーに価値がある場合、noindexやcanonicalタグを組み合わせる別の戦略も考えられる。ただし一般的には内部検索結果をインデックスさせるメリットは薄い。
大量のソート・フィルタページ
事例: アパレルECサイトD社
- 商品一覧ページにカラー、サイズ、価格帯、ブランド、在庫の有無など多彩なフィルタがあり、URLパラメータが増殖しがち。
- 「在庫あり」「在庫なし」「価格昇順」「価格降順」「○○ブランドのみ表示」など、組み合わせで膨大なページが生成される。
対応:
- 基本は、主要カテゴリページや人気の高いソートパターン(ユーザー利用が多いなど)だけインデックスさせ、それ以外の細かい条件ページはnoindexを付けるか、あるいはrobots.txtでブロックする。
- ただしnoindexを付ける場合はクロールを許可し、
noindex, followなどで商品詳細ページへのリンクをたどれるようにすると、クローラはリンク経路を把握できるので新商品追加時にもスムーズに認識が回る。 - 大量ページを全部ブロックするとリンク構造が途切れてクローラが商品詳細ページへ到達できなくなるケースがあるため、やみくもにrobots.txtで遮断するのは禁物。特に新着商品へのアクセス導線が検索エンジン的に切られると重大な機会損失につながる。
noindexとrobots.txt以外の関連要素
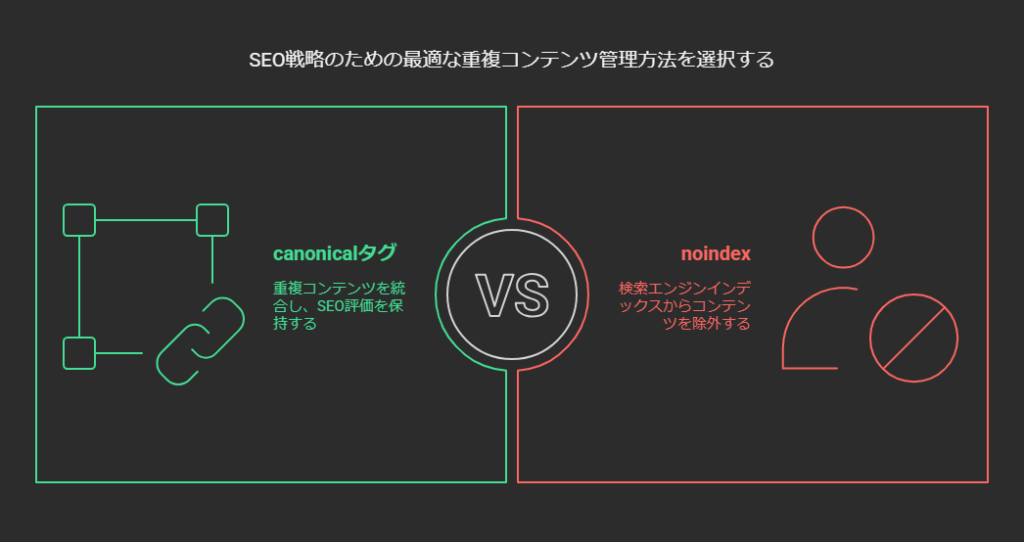
canonicalタグ
重複コンテンツ対策として広く使われるのがcanonicalタグです。重複する複数URLが存在する際、「正規のURLはこれです」と通知して検索エンジンの評価を一つに集約させる効果があります。
たとえば /product?sort=price_asc と /product?sort=price_desc が実質同じ商品の一覧を表示するなら、どちらか(あるいは両方)に<link rel="canonical" href="/product">を入れてメインのURLに集約させると、検索エンジンにとっても明確です。
ただし、「表示させたくない」というより「一本化してSEO評価を保ちたい」場合にcanonicalは有効で、完全に削除したいならnoindexまたは404/410返却といった別の手段が必要です。canonicalタグとnoindexを同時に入れた場合はnoindexが優先されるという点も覚えておきましょう。
パスワード保護・認証
本質的に外部に見せたくないページは、パスワード保護やアクセス制限をかけるのが最強かつ確実です。noindexやrobots.txtはあくまで「検索エンジンへのお願い」であり、不正アクセスや悪意あるクローラ対策にはなりません。EC運営者は個人情報や受注管理などの機密性が高い領域を含むため、サイト設計段階で厳格なアクセス制御を盛り込むことが肝要です。
Search Console/Bing Webmasterツール
インデックス状況を確認し、問題を素早く察知するためには、Google Search ConsoleやBing Webmasterツールを活用しましょう。
- 「インデックス カバレッジレポート」や「URL検査ツール」を見れば、noindexが正しく機能しているか、robots.txtでブロックされているかなどが分かります。
- もし「意図しないURLがインデックスされている」と判明した場合、素早くメタタグやrobots.txtの設定を見直し、再クロールをリクエストするなど対応が取りやすくなります。
代表的なQ&A
Q:テスト用ページを一時的に検索結果に出さないようにするには?
A:基本的にはページにnoindexを付けるのが手軽です。まだ公開前でURLが知られていないなら検索エンジンに発見される確率は低いですが、念のためnoindexを仕込んでおけば万が一リンクが張られてもインデックスされにくいです。
もっと確実に外部からのアクセスを防ぎたいなら、ステージング環境へ置いてパスワード保護するか、IP制限をかけるなどの手段を取りましょう。開発途中のページをうっかり「Disallow: /」で済ませることもありますが、完全ブロックしているとクローラが検知できず、新たに公開したときにインデックスに反映されるまで時間がかかるケースがあるので注意が必要です。
Q:noindexを設定してから反映まで時間がかかるのはなぜ?
A:検索エンジンはサイトの更新頻度やページの重要度に応じてクロール間隔を調整しています。更新頻度が低いページだとクローラがなかなか再訪問しないため、noindexを付けても「古いキャッシュ」が残る期間が生じます。
対策としてはSearch Consoleの「URL検査ツール」で「インデックス登録をリクエスト」を行い、早期クロールを促すか、一時的に「削除リクエスト」機能を使って検索結果から隠すことができます。ただし削除リクエストはあくまで一時的な処置なので、根本的にはnoindexやコンテンツ削除(404/410など)で恒久対策を行うことが望ましいです。
Q:robots.txtを編集して特定のクローラをDisallowにしたのにアクセスが止まりません
A:主な原因として考えられるのは次の通りです。
- 対象のクローラが悪意あるボットで、そもそもrobots.txtを守らない
- User-agentや記述の仕方が間違っていてルールが適用されていない
- 検索エンジン側がまだrobots.txtをキャッシュしている(更新が反映されるまで時間差がある)
悪質なボットはrobots.txtを無視するため、アクセス元IPをサーバーレベルでブロックするなどセキュリティ対策が必要になる場合もあります。GooglebotやBingbotと判明しているなら、記述が正しいか(User-agent名など)再確認し、少し待ってから再度アクセスログをチェックしてみましょう。
Q:すでにrobots.txtでブロックしているページをインデックスから削除したい場合は?
A:すでに検索結果にURLが出ているものを確実に削除するには、一時的にクロールを許可し、noindexを返すか、ページ自体を削除(404/410)する必要があります。
たとえば本来見られたくないページだったために長期に渡りDisallow: /private/としていたが、そのURLが外部リンクで拡散されて検索結果に載ってしまったケースなどが典型です。一度だけでもrobots.txtを緩和してクローラにアクセスさせれば、noindexを検出してインデックスから外れます。その後、必要であれば再度Disallow設定を戻すことは可能です。ただし、再度戻した時点でnoindexは読めなくなるため、もし外部リンクが増えた場合には再びURLがインデックスに浮上する可能性がゼロではありません。この点を考慮し、そもそもパスワード保護や削除を検討するのが最善策となるかもしれません。
まとめ:ECサイトこそ徹底したインデックス制御が必要
ECサイトをはじめ、多数のページやファイルを扱うウェブサイトでは、適切なインデックス制御が売上やSEOパフォーマンスを左右する大きな要因になります。誤設定で重要ページをクロールブロックしてしまい、商品が検索結果から一時的に消えると売上に直結する痛手を被る恐れがあるからです。また、カートページやマイページなど「見られては困るページ」が外部リンクをきっかけに意図せずインデックスされてしまったり、あまつさえユーザーの個人情報が流出したりすると、信用問題にかかわります。
noindexメタタグとrobots.txtは簡単に導入できる反面、それぞれの役割を誤解して運用する方が少なくありません。あらためて次のポイントを押さえましょう。
- **noindexタグは「検索結果に表示しないで」**と伝えるもの(インデックス制御)。
- **robots.txtは「そもそもクローラにアクセスしてほしくない」**場所を指定するもの(クロール制御)。
- クローラがページを取得できないとnoindexは効かない(=robots.txtでブロックするとメタタグが読まれない)。
- 本当に見られたくない機密情報は認証やアクセス制限で守る(noindexやrobots.txtはあくまで検索エンジンへの指示・要望)。
ECサイトの運営者が特に注意すべきは、「商品ページやカテゴリページはしっかりクロールされたいが、カートや会員限定ページは検索結果に出したくない」といった多様な要件が同居している点です。ページごとに「クロール制御が必要か」「インデックス制御が必要か」を整理し、それぞれ適切な手法を選ぶというプロセスを、サイトリニューアル時や大規模な新規ページ追加時などに定期的に実施してください。大規模なサイトほど、放置しているといつの間にか検索結果がゴミURLだらけになったり、逆に有力商品ページがなぜかインデックスされていない等の問題が起きやすくなります。
さらに、Google Search ConsoleやBing Webmasterツールを活用してインデックス状況をこまめにモニタリングし、問題発生時には迅速に原因を特定する体制を構築することが望ましいです。ECサイトの場合、新商品や新コンテンツが正しくインデックスされるかどうかが売上に直結するため、運用段階でのチェックや運営チーム間の情報共有も欠かせません。
おわりに
本コラムでは、noindexメタタグとrobots.txtによる検索エンジン向けのインデックス制御について、特にECサイトの観点を交えて解説しました。要点をまとめると以下のとおりです。
- noindex: ページをインデックスから除外するための「検索結果には出さない」指示。クローラがページを取得できる状態で初めて効果を発揮。カートページやログインページなど検索結果に不要なページで必須。
- robots.txt: クローラのアクセスを許可・禁止するための「クロール制御」ファイル。ページそのものを見せたくない、あるいはクロールバジェットを節約したい場合に使用。ただし検索結果から「URL自体を消す」わけではない点に注意。
- 運用のポイント: 「noindexで確実にインデックス除外したいページはrobots.txtでブロックしない」「ECサイトの検索結果ページやソート違いページをどう扱うか」「認証保護が必要な機密ページにrobots.txtだけでは不十分」など、運営規模や方針に応じて運用ルールを明確にすることが大切。
ECサイトの魅力を最大限に伝え、ユーザーが求める商品ページはきちんと見つけてもらいつつ、不要ページは徹底して排除する。そうしたメリハリあるインデックス制御が、SEOとユーザビリティ双方の観点でサイトの評価を高めてくれます。定期的に設定を見直す習慣をつけ、常に最新の検索エンジン情報やツールを活用しながら、適切なインデックス管理を実践していきましょう。

